Scenario
Imagine in our application we need to update a value that is shared between all requests. It means we should control concurrent requests for manipulating this shared resource. Somehow we should serialize the access to resources. In our example, we keep this value in the Redis cache to reduce latency. Here the distributed lock manager comes into the picture.
To make our example more clear, imagine we have a contribution amount that is updated by each request. This value should be plus the contribution amount of incoming requests.
Let’s demonstrate our scenario with graphic symbols for better understanding.
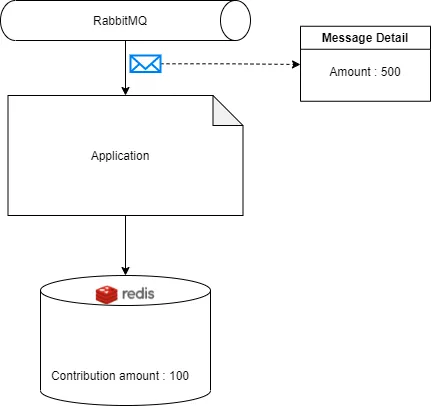
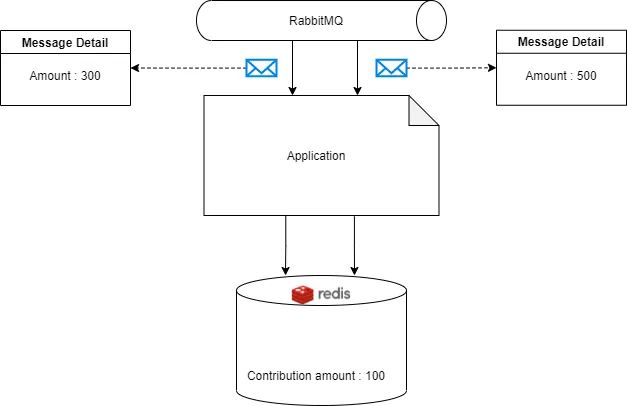
We have an application that has subscribed to a RabbitMQ queue. In the simplest model, we receive a message from the queue and update our contribution amount in Redis in synchronized mode, which means the application process requests one by one. Everything looks fine.
Problem
We may encounter two problems :
1- What if the application uses async processing to process messages from the queue?
2- What if we horizontally scale the application, which means running several instances of the application?
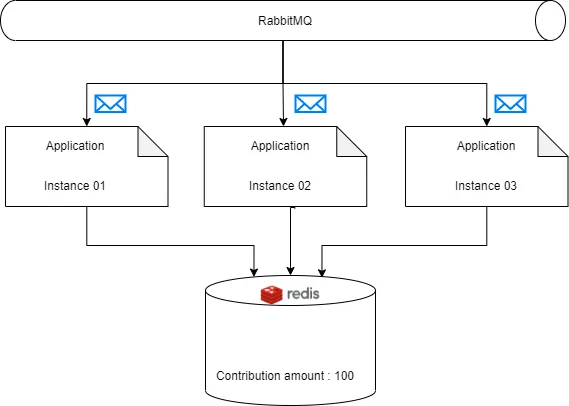
In these two cases, we will receive more than one request, and somehow the concurrency should be controlled, otherwise, we will face Race conditions in Redis and the contribution value will not be valid anymore.
The first solution that can be brought up is to use an internal lock object for controlling the critical point.
This solution works well for the first problem. But what about the second one?
In the case of horizontal scaling, the internal lock just works in the scope of one instance, we should find a control mechanism outside of the application scope.
Solutions
1- Actor systems like Akka or Orleans(.Net)
2- Distributed lock manager (DLM)
3- Partioninig Kafka Topics Based on a key
3- Add your solutions here
In my point of view if your application does not have to deal with lots of concurrent scenarios like what I’ve mentioned, using a DLM is better for the sake of simplicity. Because implementing actor systems brings more complexity to your projects.
But if you have an application with lots of critical points in which concurrency should be controlled, I also prefer to use actor systems. The point is, in the example I’ve mentioned, we just need to control access for a single shared value. So I prefer to use DLM instead of bringing extra complexity to my application code.
Ok, forget the Actor systems, and Let’s talk about DLM and how it can be helpful for our problems 😊
For implementing a DLM we have several choices. for example, we would use Zookeeper or Redis or maybe other tools. As I have experience with Redis DLM, I’ve decided to explain it in this article.
I don’t want to talk about Redis DLM in-depth, because it’s already been explained well on Redis Official website .
I’ve just tried to define a scenario and solve it with the help of Redis DLM.
A Redis Enterprise cluster node can include between zero and a few hundred Redis databases in one of the following types:
· A simple database, i.e. a single master shard
· A highly available (HA) database, i.e. a pair of master and slave shards
· A clustered database, which contains multiple master shards, each managing a subset of the dataset (or in Redis terms, a different range of “hash-slots”)
· An HA clustered database, i.e. multiple pairs of master/slave shards
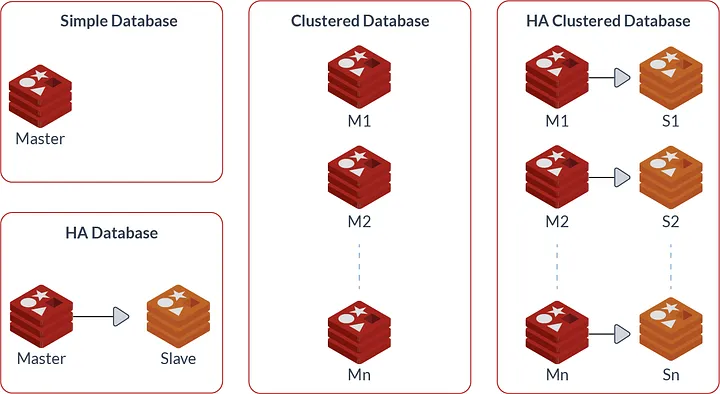
I made contact with the Redis development team and I asked about Redis DLM best practice. As they said, using clustered Redis with more than 2 Master nodes. Although you can use the RedLock algorithm with One Master and several slaves ( leader-follower model).
Before starting to Implement a Redis DLM, it’s better to notice these points:
1- DLM in Redis uses the RedLock algorithm to control lock management.
2- We have several implementations of the RedLock algorithm in different languages(Redis Website) and you do not need to implement it again.
3- Our lock manager also should be configured with an expiration time for locks, because without an expiry time you may face deadlock, to avoid this it’s better to set an expiry time. It means after that time the lock will be released automatically by Redis.
4- We also should create a mechanism as a retry pattern to retry for acquiring the lock. If the requests couldn’t get the lock, we should consider it as a failed request and it should be controlled ( for example we can republish the failed request to the queue, to receive it again or we could use an outbox pattern to process them in a background worker.)
5- I highly recommend you find an implementation of RedLock in your language that supports the retry pattern and the expiry time for the lock.
So let’s define our scenario step by step with the help of Redis DLM.
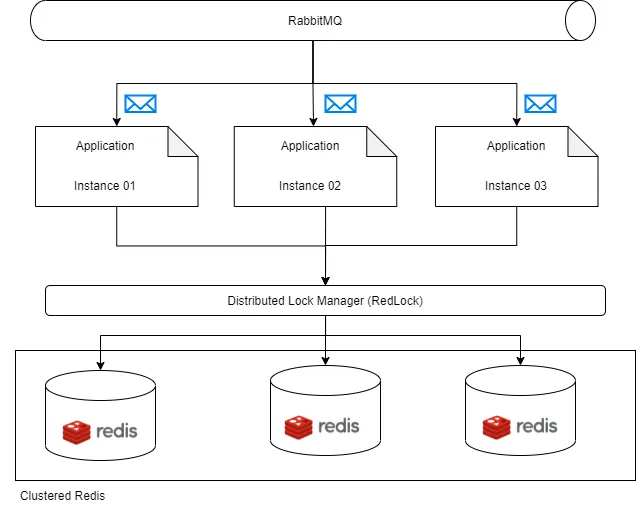
1- We have an application that has subscribed to a queue
2- We use async processing and also we want to horizontally scale our application which means we will have several handlers for a specific queue, and we will receive several messages simultaneously.
3- All the requests want to update a contribution value which is located inside the Redis cache. It means our shared resource is the contribution value and concurrency should be controlled for updating this value in Redis.
4- We use Redis distributed lock manager (DLM) as a coordinator to serialize the access to this contribution amount.
5- each request that wants to update the contribution amount should acquire a lock from DLM, if it acquired the lock it could be able to update the contribution amount in Redis.
Conclusion
In modern applications in which async processing and horizontal scaling can be considered a Must-have, we will face concurrent requests, and If we have some shared resource, somehow this concurrency must be controlled.
For controlling concurrency in applications we could implement different approaches, but you should always consider choosing the best approach because a good developer avoids bringing unnecessary complexity to an application by over-designing or overthinking.
So, for concurrency management in an application, first, you must understand the problem, after that determine your critical points, and in the last step according to the collected data and consulting with a domain expert, you can choose your approach. Distributed lock managers in most cases can handle your problems. But sometimes you have to choose another approach like Actor systems.
That’s all, Hope you’ve enjoyed the article, feel free to contact me and send me your comments.
Cheers, Matt Ghafouri