When We talk about the deployment and management of any application on Kubernetes there are two main approaches:
Stateless : Stateless applications don’t store any persistent data or state between requests, making them inherently scalable and easy to manage. on K8s we can achieve a stateless application by using k8s Deployments feature.
Stateful : Stateful applications, in contrast to stateless ones, retain persistent data or state between requests, often requiring stable identities and storage for proper functionality, and with the help of the StatefulSets feature we are able to have a stateful application hosted on k8s.
But Before going any further let’s have a childish definition for these terms.
Stateless Application
Think of a robot playing hide and seek. In each round, the robot doesn’t remember where it hid before; it starts fresh every time. This is similar to a stateless application in Kubernetes. Each time you ask the robot where it is, it calculates and tells you without remembering the past. For example, a simple calculator app on your phone is like a stateless application – it doesn’t remember the previous calculations; it just computes the new ones.
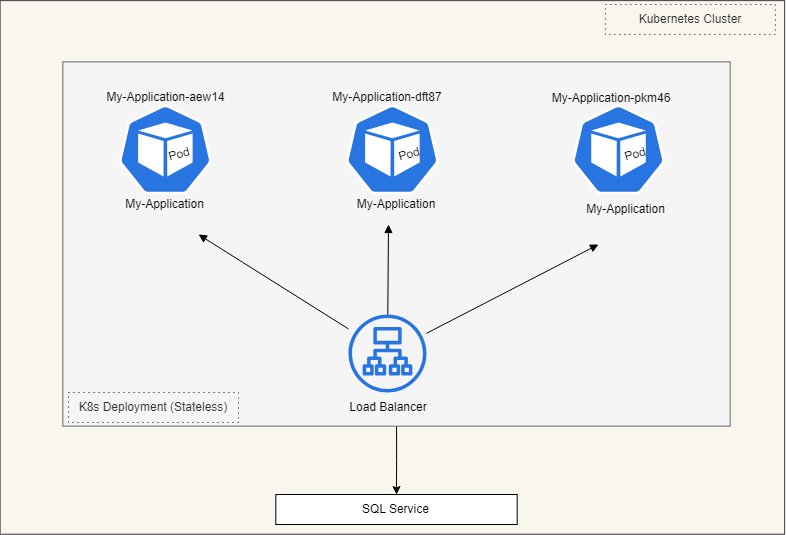
Diagram
Following the “My-Application” name, random IDs are appended. If the Pod restarts or is scaled down, the Kubernetes Deployment object will assign new random IDs to each Pod upon restarting. All these Pods are linked to a single load balancer service.
Stateful Application
Now, imagine playing a memory card game where you flip cards and try to match pairs. In each round, you need to remember where you saw each card because it helps you find the pairs. This is like a stateful application. It holds onto information between rounds, just like remembering where the cards are in the memory game. An example in the digital world is a note-taking app. It remembers the notes you wrote, even if you close and reopen the app later.
Diagram
Let’s check this SQL Server service which is hosted with StatefulSet on k8s.
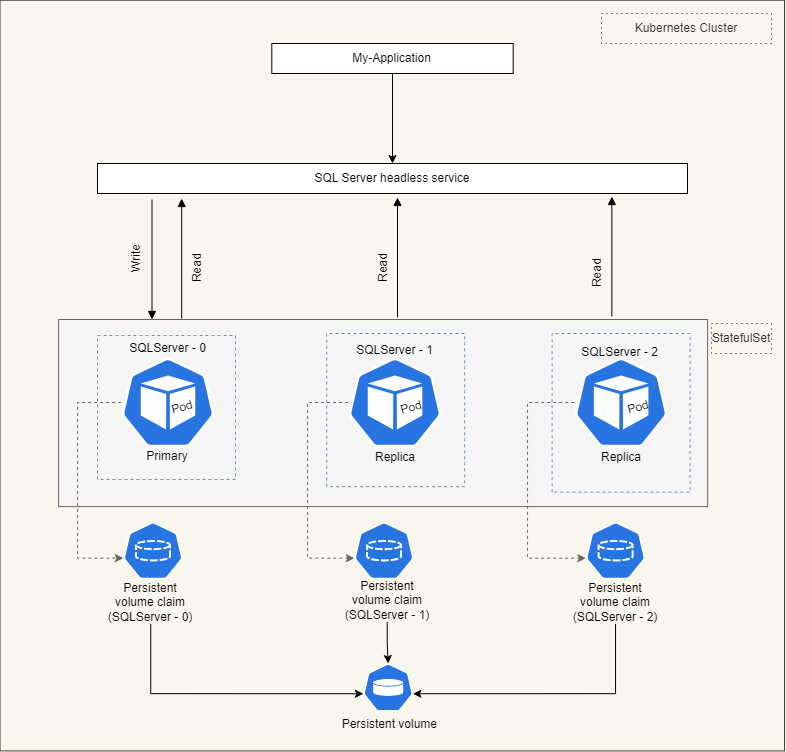
StatefulSet for SQL Server with 3 pods (1 master, 2 replicas) ensures stable network identities, ordered deployment, and persistent storage. The master handles read and write operations, while replicas provide scalability and data redundancy. StatefulSet’s controlled termination safeguards against data loss during scaling down.
But Why we should use Statefulset?
Stable Network Identity
StatefulSets provides stable network identities for each pod. This is crucial for databases because it ensures that each instance of the database has a predictable and stable network identity, making it easier to manage connections and configurations.
Ordered Deployment and Scaling
StatefulSets deploy and scale pods in a predictable and ordered manner. Each pod is given a unique and stable hostname based on the specified naming convention. This is important for databases because it ensures that pods are started and stopped in the correct order, avoiding issues with data consistency.
Persistent Storage
StatefulSets allows you to use persistent volumes (PVs) and persistent volume claims (PVCs), which are essential for databases that require persistent storage. With StatefulSets, each pod gets its persistent storage, and the data is retained even if the pod is rescheduled or replaced.
Ordered Termination
When you scale down a StatefulSet, the pods are terminated in a controlled and orderly fashion. This is critical for databases to ensure that data is not lost or corrupted during the scaling-down process. It means you can terminate any replica pods, but terminating the Master one is not a good idea.
In the world of computers and Kubernetes, understanding whether an application is stateless or stateful helps us manage and use them effectively.
So, stateless applications are like a robot in hide and seek that starts fresh each round, and stateful applications are like playing a memory card game where you need to remember things from one round to the next.
Real World Examples
Stateless Application
Here are some examples of stateless real-world applications:
- Static Website: A simple website with fixed content that doesn’t change based on user interactions
- Content Delivery Network (CDN): Services that distribute web content (images, stylesheets, scripts) globally
- API Gateway: An entry point that manages and directs requests to various microservices in a system
- DNS Server: Domain Name System servers that translate domain names into IP addresses are typically stateless
These applications benefit from statelessness by being easily scalable, highly available, and more fault-tolerant in distributed and cloud environments.
Stateful Application
Stateful application examples can be Elasticsearch, Cassandra, Kafka, RabbitMQ, Prometheus, etc. They all use StatefulSe. Let’s dig a bit more about Kafka and how it benefits from StateFulSet:
Kafka benefits from using a StatefulSet in Kubernetes due to its distributed and stateful nature. Here are key reasons why Kafka benefits from StatefulSets:
- Stable Network Identities
Kafka relies on stable and unique network identities for each broker within a cluster. StatefulSets provide stable hostnames, allowing clients and other components to reliably communicate with Kafka brokers, even after pod restarts or rescheduling.
- Ordered Scaling
StatefulSets ensure that Kafka brokers are scaled in a predictable and ordered manner. This is crucial for Kafka, where the addition or removal of brokers should follow a specific sequence to maintain the integrity of the cluster.
- Persistent Storage
Kafka requires durable and persistent storage for its logs. StatefulSets support the use of Persistent Volumes (PVs), allowing Kafka brokers to maintain their log data even when the pod is rescheduled or restarted.
- Service Discovery
StatefulSets automatically creates a headless service in Kubernetes. This facilitates service discovery, allowing other components in the system to locate and connect to individual Kafka brokers through DNS.
- Rolling Upgrades
StatefulSets support rolling updates, allowing Kafka to be upgraded one pod at a time without disrupting the entire cluster. This ensures continuous availability during the upgrade process.
In summary, Kafka’s reliance on stable network identities, ordered scaling, persistent storage, service discovery, and seamless upgrades make StatefulSets a suitable choice for deploying Kafka clusters in Kubernetes.